Why Unpaywall will be a game-changer
Oh god, not another post about Open Access.
Yep, sorry, we’re going to keep talking about this stuff, because it’s something worth talking about.
Recently, a new tool has come out, from the makers of OADOI and ImpactStory, that allows users to ‘jump the paywall’ and access research articles for free. It’s called Unpaywall, and it works by using information contained within papers, such as its DOI, to find legally archived versions of papers (of which there are multiple usually, like pre-peer review, post-peer review but pre-typesetting etc.) from across the Web, and deliver them straight to you. The interface is fairly simple, as it exists on pretty much any webpage that links to a research paper, with a colour code letting you know whether a version is available for free or not. Click away and you’re done, simples.
It leverages what is known as ‘green open access’, or self-archiving, something which is becoming way more common as some research funders mandate it as part of an OA policy, and as we move generally as a research culture from being closed and selfish (for whatever reason) to one of open sharing.
Now, as you might expect, Unpaywall got a lot of nice media coverage, as it’s a fairly disruptive technology. But a lot of the coverage was fairly superficial to me, and didn’t explore the wider implications of Unpaywall within the current system of research culture and scholarly communications. So here’s a few things that I think are worth considering a bit further (still work in progress in my head too atm).
- It’s legal and risk-free
“We think Unpaywall offers a more sustainable approach by working within copyright law and supporting the growing open access movement.” (source) Couldn’t agree more. This is important as other sites like SciHub, which has around 60 million research articles, are not exactly legal (in many countries) due to the fact that they host paywalled content rather than free versions of it. They also detract from the need for researchers doing OA in a sustainable manner though self-archiving, which is itself a legal, sustainable, and risk-free approach to making all of your work OA for free.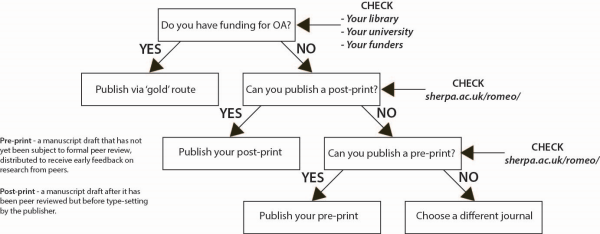
Made by me, CC BY - It encourages a shift in research culture
Related to the last point above, Unpaywall only works because researchers self-archive their work. At some point, a threshold must be met, whereby so much content is available for free now, that there is no need to pay for subscriptions any more, and library (and individual) budgets become available for more useful things. But to achieve this, researchers actually have to continue to archive their work. And not just future research, but historically published content where available too. This is part of an evolving research culture and academia, whereby sharing and transparency are becoming the norm over traditional ‘closed’ practices. This means that we as a collective have to do more to understand things like journal/funder policies, what embargoes are and why they exist, versioning of articles and production processes, licensing and copyright, the ‘why bother’ of Open Access, and the impact this will all have. Self-archiving your work should become as natural a part of the research process as email, Dropbox, making a coffee, and all the other simple things we do, because it really is that simple.While Unpaywall does leverage platforms like Academia.edu and ResearchGate, an option which can be turned off, due to the questionable legality of many articles on these platforms we might see more researchers choosing institutional repositories or preprint archives instead. As these things become better maintained and more common, I think we’ll see growth away from these platforms and towards integrated ‘green’ OA instead.
- It’s free and easy to use for anyone
Publishing OA still can cost a lot money, depending on the journal you choose and your funding options. Self-archiving is always free for users, and often far easier than navigating nightmarish journal submission platforms. Unpaywall is free, installed into your browser at a click, and activated for individual articles with another. Simplicity leads to popularity, and it is way, way, WAY easier than having to be at a place with institutional access, using a VPN, emailing authors, using inter-library loan, and all the other work arounds we have for our broken scholarly publishing system.Anything which is saving researchers time and money is a good thing.
- It’s integrated into existing infrastructure
Unpaywall leverages the power of existing platforms as data sources, including PubMed Central, the DOAJ, Crossref, DataCite, Google Scholar, and BASE. It makes all of the magic it does with this available for anyone via their OADOI API, which is awesome. As someone who uses (and works for) ScienceOpen, it also works really well for that, across 30 million article records (and growing), providing in my mind a really awesome alternative to things like Google Scholar.
Like on this popular Nature paper at ScienceOpen (source) - It can (and will) be combined with the OA Button
@pcmasuzzo @Protohedgehog @OA_Button we have an integration with @OA_Button's awesome author request system coming out soon…
— Unpaywall (@unpaywall) May 1, 2017
The Open Access Button is another awesome piece of community-led technology that allows users to request OA versions of papers directly from the authors themselves. It too exists as a browser plugin, and could (and seems probably will be) extended to use with Unpaywall so that if it can’t find an OA version of a paper, OA Button automatically requests it for you. How awesome would that be?
As always, what do you think? Will these tools be a game changer? What impact do you see them having? Are they having any personal effects on you? Let me know in the comments!
It would have more impact if oadoi could be integrated into discovery layers in libraries. Right now, we have to hope enough people use this add-on. It would be far more impactful if anyone using a library catalog would have a similar feature. Unfortunately, I don’t see a straightforward way to do that at the moment. I’m thinking hard about it though.
Have I got good news for you! Libraries CAN in fact integrate this their existing systems by using oaDOI data in their link resolvers. When library users click a link, they can be redirected to OA copies when those resources are missing from library holdings. Over 600 libraries are using oaDOI in this way, largely via our SFX integration. Check it out! http://blog.impactstory.org/oadoi-in-sfx/
[source: I’m one of the oaDOI developers]
Your graphic on Free Legal OA, reminds me of this one: https://svpow.com/2013/05/11/the-sv-pow-open-access-decision-tree/
It hangs on my cube wall, and veeery occasionally someone takes a look at it.
Now, can we get unpaywall installed on all the university student workstations as a matter of course…..
Hello, Your example in point 4 does not lead to the article but to a “page not found” on academia.edu.
Hi Andy, which example, sorry? The ScienceOpen one in point 4? The link seems to work here: https://www.scienceopen.com/document?vid=199f447f-9324-4a80-b0a4-8b367a2af5f8 I don’t see any for academia.edu..
Great article. Unpaywall is important. We’ve been building a tool to “unpaywall” paywalled citations on Wikipedia by adding marked free-to-read versions alongside closed citations. There is a lot we can’t get without academia.edu and researchgate, but they pose both ethical and copyright compliance issues. With Unpaywall it’s less of a concern since it’s just a utility, but with our tool OAbot (developed by/with Antonin Delpeuch of Dissem.in), the impact would be visible and concrete in the placement of a valuable link on and from Wikipedia. What do you think. Should OAbot give a “scholarly network” option like Unpwayall, or not go there at all?
Yes
I added unpaywall but have not found a single example where it found a paper that Google Scholar did not. Don’t get me wrong, I’d rather not rely on Google but have always done so, and wanted to test it out to see if it was somehow more powerful. I have not paid much attention to the other direction–that is when Google Scholar finds an article, does unpaywall ever miss it?
Hi Glen,
So Google Scholar also indexes a lot of content that has been uploaded in breach of copyright (eg via ResearchGate). Unpaywall explicitly finds legal version of self-archived articles, thereby providing access in a sustainable way that encourages research communities to legally commit to Open Access. I don’t think anyone has done a direct comparison yet between Google Scholar and Unpaywall in terms of ‘green OA discoveribility’, but that would be interesting.
As someone without the privilege of institutional access, Google Scholar is much less useful to me now, as although it is great for discovering articles, it is much less useful for discovering ones without paywalls!
Cheers,
Jon